BetaHub Blog

Devlog: We've Implemented Bug Search Engine with MeiliSearch and Rails 7
May 27, 2024 · 9 min read
We did a thing. With the release of Gray Zone Warfare, BetaHub had to scale fast to collect all the user bug reports and make good use of them. Having a database is one thing, but making use of the data is a totally different story.
One of the features on the roadmap that we had to implement quickly was the search feature. When people think “search,” they usually think ElasticSearch. While ElasticSearch is a solid solution, I’m somewhat against setting up memory hogs that come with tons of (mostly useful) features that we likely won’t need at this stage. At least, that was the assumption.
After a quick research session (thanks GPT-4 and Perplexity!), I was able to list alternatives to ElasticSearch and learned about MeiliSearch (you can’t imagine how often I had to check my notes to remember this name—who came up with it?! Therefore, I will be calling it MS from time to time). It’s written in Rust, and it’s fast and lightweight on memory. At least, that’s what everyone was saying.
Installing MeiliSearch
I love Docker. To download, install, and run MeiliSearch, all you need to do is execute:
docker run -p 7700:7700 -it getmeili/meilisearch:v1.8
For the docker-compose file, it would be:
meilisearch:
image: getmeili/meilisearch:v1.8
ports:
- '7700:7700'
environment:
MEILI_NO_ANALYTICS: 'false'
Note: Change MEILI_NO_ANALYTICS to true if you want to opt out of anonymous analytics.
Then, you can access it both from your web browser and your apps using the URL: http://localhost:7700.
The Concept
MeiliSearch consists of indexes that can hold JSON-like documents. All you need to do is post these documents, and you can search through the entire collection.
MeiliSearch determines the order of returned items by rank, which is calculated based on several configurable factors. In most cases, the defaults work fine, but we’ll get to tuning them later.
Installing the Rails Gem
Just add:
gem 'meilisearch-rails'
to your Gemfile, then execute:
bundle install
bin/rails meilisearch:install
Edit your config/initializers/meilisearch.rb file if needed. The default file might look like this, but we recommend adding per_environment: true to differentiate between development and test environments:
MeiliSearch::Rails.configuration = {
meilisearch_url: ENV.fetch('MEILISEARCH_HOST', 'http://localhost:7700'),
meilisearch_api_key: ENV.fetch('MEILISEARCH_API_KEY', 'YourMeilisearchAPIKey'),
per_environment: true
}
GitHub page of the gem: https://github.com/meilisearch/meilisearch-rails
Configuring Your Model
We’re using the Issue model to hold all the bugs, so we did something like this:
class Issue < ActiveRecord::Base
include MeiliSearch::Rails
belongs_to :project
meilisearch(synchronous: Rails.env.test?) do
attribute :title, :description, :status, :project_id
searchable_attributes [:title, :description]
filterable_attributes [:status, :project_id]
end
end
Note that in the test environment, we’re passing synchronous: true so we can do the indexing and testing without any issues.
There’s a problem with the above setup, specifically with the project_id field. MeiliSearch tries to identify the primary key based on field names, treating fields that end with “id” as primary keys. If there are multiple such fields (like id and project_id), you won’t be able to add the record unless the index knows which field is the primary key. We fixed this by renaming project_id to project.
To search through the fields, implement a simple controller method:
def search
@issues = Issue.search(params[:query], {
filter: [
"status NOT IN ['hidden', 'duplicate']",
"project = #{@project.id}"
],
limit: 50
})
end
(Note that we’re still using project_id here, but project in the configuration).
This executes a MeiliSearch query and assigns the resulting ActiveRecord objects to the @issues field.
Relevancy Tuning
We want to ensure that the most relevant results appear at the top. MeiliSearch has a ranking system that’s good, but we wanted to improve it.
Typo Tolerance
As the documentation states, typo tolerance is enabled by default, with one typo for five characters and two for nine. Our dataset consists of many difficult words, so we adjusted this to four and eight, respectively.
Synonyms
This was tricky. While there is synonyms support directly in MeiliSearch, we decided not to use it. We had a synonyms.json file that was 5 megabytes in size, containing many synonyms for popular words. Loading it into the search engine wasn’t a problem, but searches became significantly slower:
- Before loading synonyms: 5-10 ms, up to 50 ms per search
- After loading synonyms: 500-1000 ms per search
It seemed like it was searching for many more terms. Instead, we inverted the algorithm. We loaded matching synonyms into every record pushed into the database, in a field that should be searchable but not displayable.
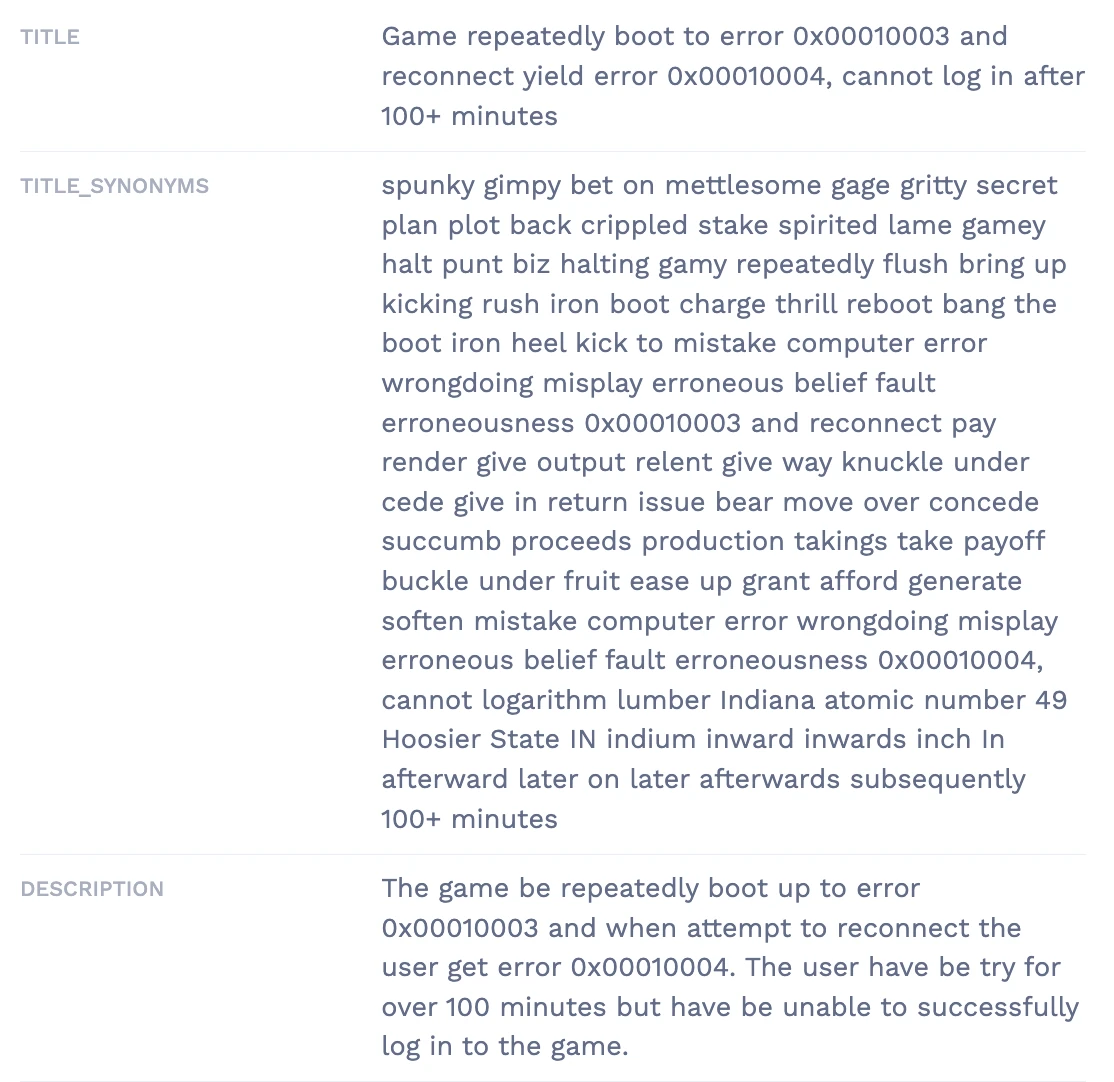
Field Priorities
Some fields are more relevant than others. We wanted the title to be more relevant than anything else, followed by descriptions and then synonyms. The documentation states that the ranking order is automatically generated by the order of indexed documents. This is true for the Rails implementation, so we defined the order as:
attribute :title
attribute :description
attribute :tags
attribute :title_synonyms
Lemmatization
Until recently, I didn’t know what lemmatization was, so here’s a brief explanation.
Lemmatization reduces words to their base or dictionary form, called a lemma, considering the context and part of speech. This helps in processing natural language more effectively by treating different forms of a word as a single item.
Example
Sentence: The children are running and have run many times before.
After Lemmatization: The child are run and have run many times before.
Matching lemmatized words is much easier than matching non-lemmatized words.
For Ruby, there’s a somewhat outdated but functional gem called lemmatizer. Just make sure to fetch it from the master branch by adding the following to your Gemfile:
gem 'lemmatizer', github: 'yohasebe/lemmatizer', require: true
Then you can load and use the lemmatizer with:
lemmatizer = Lemmatizer.new
lemmatizer.lemma(word)
Two issues with this code are:
- You need to lemmatize your content word by word, which can be somewhat addressed with
split(' '). - Creating a new lemmatizer instance loads a large dictionary. This takes time, so you don’t want to load it every time you lemmatize something, but you might not want it to stay in memory at all times either.
In BetaHub’s case, we used a weak reference so the lemmatizer would unload itself whenever the garbage collector is called:
def self.lemmatize(text)
return text if text.blank?
text.split(' ').map do |word|
begin
@_lemmatizer ||= WeakRef.new(Lemmatizer.new)
@_lemmatizer.lemma(word)
rescue WeakRef::RefError
@_lemmatizer = nil
retry
end
end.join(' ')
end
We updated our attribute fields to lemmatize the text before indexing:
attribute :title do
Issue.lemmatize(title)
end
attribute :description do
Issue.lemmatize(description)
end
Custom Field Sorting
BetaHub uses something we call the Heat to indicate how “hot” an issue is. Hotter issues should receive more attention and therefore should appear higher on the list.
Fortunately, MeiliSearch has configurable ranking rules where we can easily change the importance order and add field-sorting rules. We defined Heat as one of those rules:
ranking_rules [
"words",
"typo",
"proximity",
"attribute",
"sort",
"exactness",
"heat:desc",
]
Some Gotchas
Do Not Use “*_id” Fields
I ran into an issue where MeiliSearch was trying to resolve a *_id field as a primary key, and having two of these fields caused it to reject the document. To avoid this, rename your _id-ending attributes:
attribute :project do
project_id
end
Auto-Indexing Can Be Unpredictable
For simple Rails projects, the auto-index feature updates the index whenever model attributes are updated. However, with custom attributes, you need to implement helper methods so MeiliSearch knows when to index. For me, this was too unpredictable, so I disabled auto-indexing:
meilisearch(synchronous: Rails.env.test?, auto_index: false) do
...
end
I defined callbacks to manage indexing manually:
after_save :index!, if: -> {
title_changed? || description_changed? || heat_changed?
}
after_create :index!
before_destroy :remove_from_index!All necessary methods are already provided by MeiliSearch, so no additional implementation is needed.
Summary
As of today, we’ve uploaded 28,679 bug documents to MeiliSearch. The search engine is fast, with most searches taking less than 10 ms, sometimes up to ~20 ms. The majority of the time is spent on the Rails side, but in the result, a HTTP request can respond to a query between 100 and 150 ms, which is still acceptable.
In overall, we’re happy with the results. The search is fast, and the results are relevant. We’re still monitoring the performance and will make adjustments as needed.
If you want to discuss our implementation or have any questions, feel free to reach out to us on Twitter (X) or Discord!
Join for free today
Supercharge your team with the best bug tracking and player feedback tools. No credit card required, forever free.

Our Mission
At BetaHub, we empower game developers and communities with an engaging platform for bug submission. We foster collaboration, enhance gaming experiences, and speed up development. BetaHub connects developers, testers, and players, making everyone feel valued. Shape the future of gaming with us, one bug report at a time.


2026 © Upsoft sp. z o.o.